Machine learning in cyberbeveiliging
Arthur Samuel, pionier op het gebied van kunstmatige intelligentie, beschreef AI als een reeks methoden en technologieën waarmee 'computers het vermogen krijgen om te leren zonder dat ze expliciet hiervoor geprogrammeerd zijn'. In een specifiek geval van lerenonder toezicht voor anti-malware, kan de taak op de volgende manier worden geformuleerd: met een reeks objectfuncties \( X \) en bijbehorende objectlabels \( Y \) als input kan een model worden aangemaakt dat de juiste labels produceert \( Y' \) voor eerder onbekende testobjecten \( X' \). \( X \) kunnen enkele functies zijn die de inhoud of het gedrag van bestanden weergeven (bestandsstatistieken, lijst van gebruikte API-functies, enz.). Labels \( Y \) kunnen gewoon 'malware' of 'onschadelijk' zijn (in complexere gevallen zou een gedetailleerde classificatie, zoals virus, trojan-downloader, adware, enz., nuttig zijn). In het geval van leren zonder toezicht zijn we meer geïnteresseerd in het onthullen van de verborgen gegevensstructuur, bijvoorbeeld het vinden van groepen vergelijkbare objecten of zeer gerelateerde kenmerken.
De meerlaagse beveiliging van de volgende generatie van Kaspersky maakt uitgebreid gebruik van AI-methoden in alle fasen van de detectie, van schaalbare clustermethoden voor het vooraf verwerken van de inkomende stroom bestanden in de infrastructuur tot robuuste en compacte, diepe neurale netwerkmodules voor gedragsdetectie die direct werken op de computers van gebruikers. Deze technologieën zijn ontworpen om te voldoen aan verschillende belangrijke vereisten voor cyberbeveiligingsapplicaties in de echte wereld, waaronder een zeer laag aantal false positives, interpreteerbaarheid en betrouwbaarheid bij een mogelijke aanval.
We gaan kijken naar enkele van de belangrijkste technologieën op basis van machine learning die worden gebruikt in de endpoint-producten van Kaspersky:
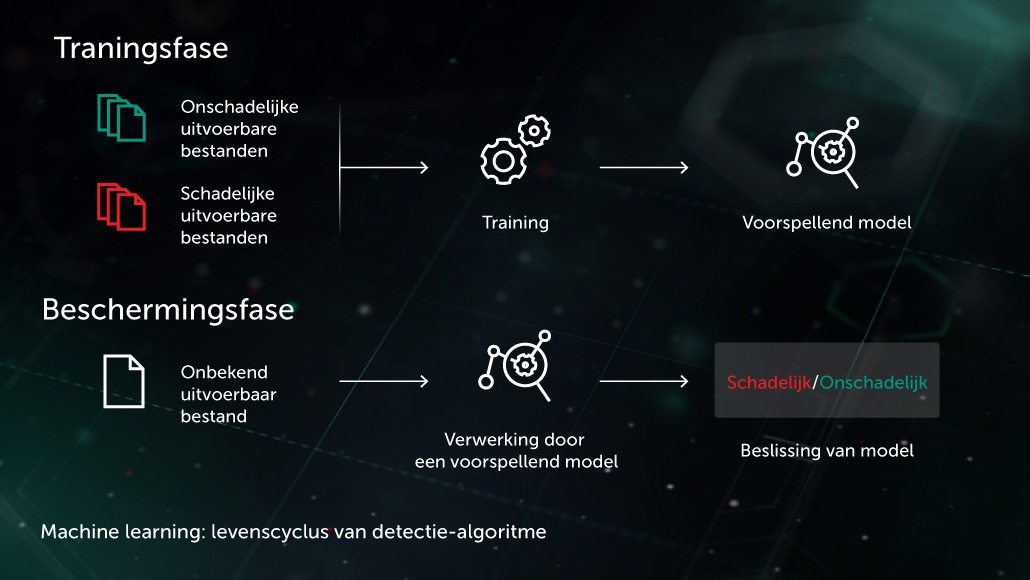
Beslissingsbomen
Bij deze benadering heeft het voorspellende model de vorm van een reeks beslissingsbomen (bijvoorbeeld random forest of gradient boosted bomen). Elke boom-node zonder bladeren bevat een vraag over kenmerken van een bestand, terwijl de nodes met bladeren definitieve beslissingen van de boom over het object bevatten. Tijdens de testfase doorloopt het model de boom door de vragen in de nodes te beantwoorden met de bijbehorende kenmerken van het betreffende object. In de laatste fase wordt het gemiddelde genomen van beslissingen van meerdere bomen via een specifiek algoritme om de definitieve beslissing over het object te bieden.
Het model profiteert van de proactieve beveiligingsfase vóór de uitvoering op de locatie van het endpoint. Een van onze toepassingen van deze technologie is Cloud ML for Android voor de detectie van mobiele bedreigingen.
Gelijkenis-hashing (locatiegevoelige hashing)
In het verleden waren hashes die werden gebruikt om 'malware-sporen' te maken, gevoelig voor elke kleine wijziging in een bestand. Deze tekortkoming werd misbruikt door schrijvers van malware middels verhullingstechnieken zoals meervormigheid op de server: door kleine wijzigingen in de malware bleef deze onopgemerkt. Gelijkenis-hash (of locatiegevoelige hash) is een AI-methode om vergelijkbare schadelijke bestanden te detecteren. Hiervoor haalt het systeem bestandskenmerken op en gebruikt leren middels orthogonale projectie om de belangrijkste kenmerken te kiezen. Vervolgens wordt compressie op basis van ML toegepast, zodat waardevectoren van vergelijkbare kenmerken worden omgezet in vergelijkbare of identieke patronen. Deze methode biedt een goede generalisatie. De omvang van de database met detectierecords wordt hierbij aanzienlijk verkleind omdat één record nu de hele serie meervormige malware kan detecteren.
Het model profiteert van de proactieve beveiligingsfase vóór de uitvoering op de locatie van het endpoint. Dit wordt toegepast in ons Similarity Hash Detection System.

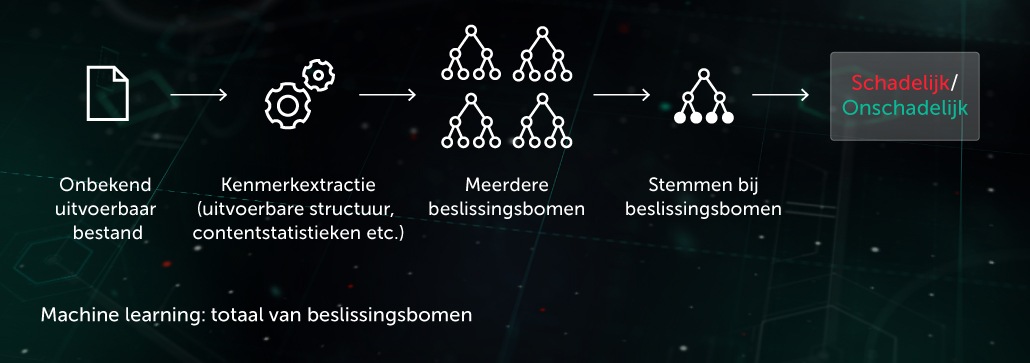
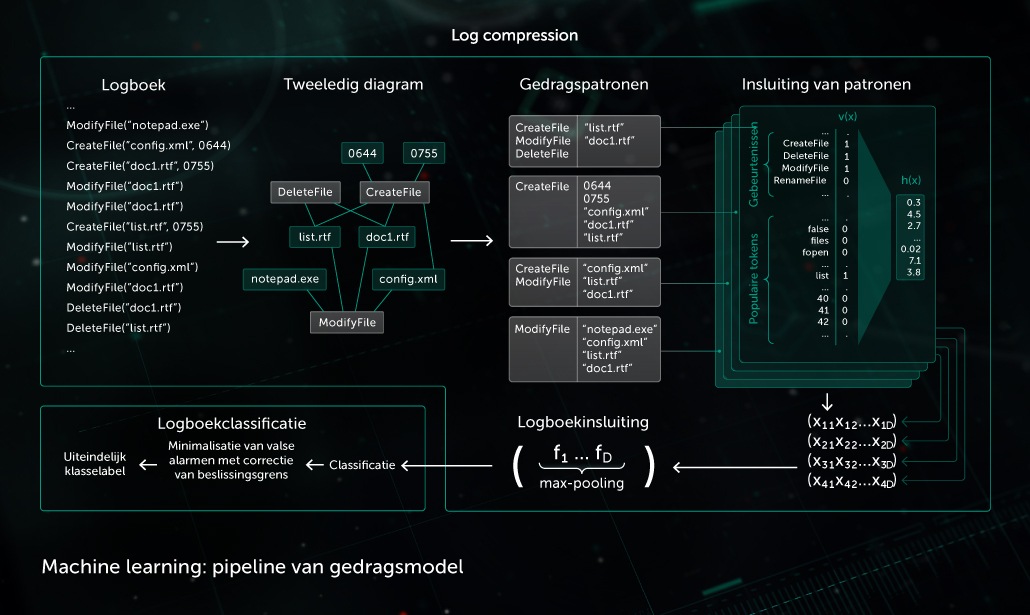
Gedragsmodel
Een bewakingscomponent maakt een gedragslogboek mogelijk: de reeks systeemgebeurtenissen die hebben plaatsgevonden tijdens uitvoering van het proces, samen met bijbehorende argumenten. Om in logboekgegevens kwaadaardige activiteit te detecteren, comprimeert ons model de verkregen gebeurtenissenreeks tot een reeks binaire vectoren en traint het diepe neurale netwerk om onderscheid te maken tussen schone en kwaadaardige registraties.
De objectclassificatie van het gedragsmodel wordt gebruikt door zowel statische als dynamische detectiemodules in Kaspersky-producten aan de endpoint-zijde.
AI speelt een net zo belangrijke rol bij het ontwikkelen van een goede in-lab-infrastructuur voor het verwerken van malware. Kaspersky gebruikt het voor de volgende infrastructuurdoeleinden:
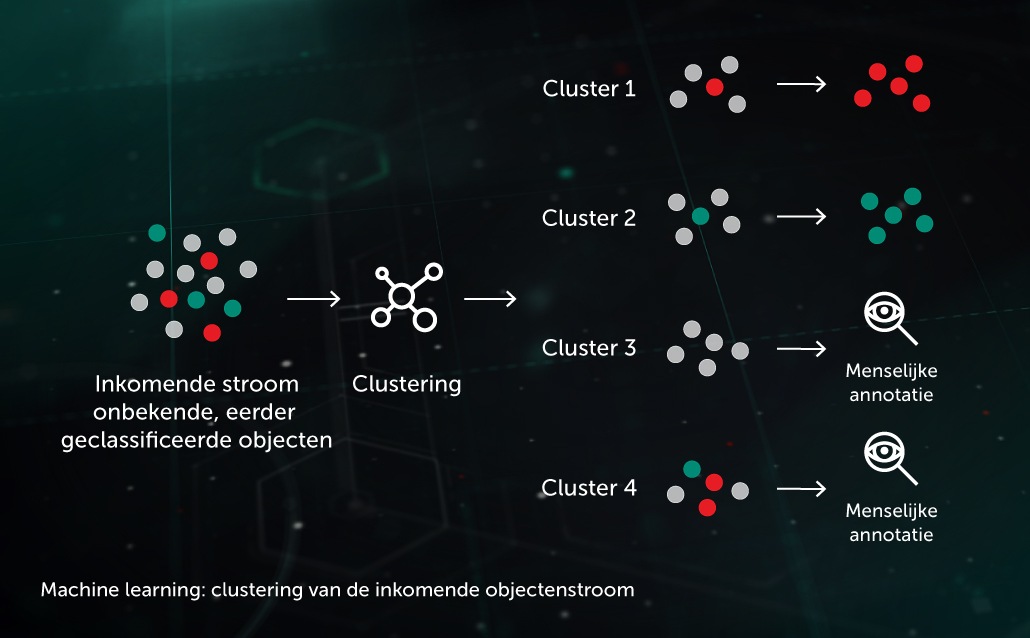
Clusteren van inkomende stroom
Dankzij ML-gebaseerde clusteralgoritmen kunnen we grote volumes onbekende bestanden op onze infrastructuur efficiënt scheiden in een werkbaar aantal clusters, waarvan enkele automatisch kunnen worden verwerkt omdat hierin een reeds geannoteerd object aanwezig is.
Grootschalige classificatiemodellen
Voor enkele van de krachtigste classificatiemodellen (zoals een enorm, willekeurig beslissingsbos) zijn veel bronnen vereist (processortijd, geheugen), samen met kostbare kenmerkextractors (verwerking via een sandbox kan bijvoorbeeld vereist zijn voor gedetailleerde gedragslogboeken). Daarom is het effectiever om de modellen in een laboratorium te houden en uit te voeren, en de kennis die is opgedaan met dergelijke modellen te distilleren door een licht classificatiemodel te trainen in de uitvoerbeslissingen van het grotere model.
Beveiliging binnen het gebruik van ML-aspecten van AI
Nadat ML-algoritmen uit het laboratorium komen en ingezet worden in de echte wereld, kunnen ze kwetsbaar zijn voor vele vormen van aanvallen die zijn ontworpen om AI-systemen te forceren om met opzet fouten te maken. Een aanvaller kan een reeks trainingsgegevens infecteren of reverse-engineering uitvoeren op de code van het model. Daarnaast kunnen hackers brute-force-aanvallen uitvoeren op ML-modellen met behulp van speciaal ontwikkelde 'vijandige AI'-systemen. Deze kunnenautomatisch meerdere aanvalsvoorbeelden genereren en ze tegen de beschermde oplossing gebruiken of tegen geëxtraheerde ML-modellen , totdat er een zwak punt in het model wordt ontdekt. De impact van dergelijke aanvallen op AI gebaseerde anti-malwaresystemen kan enorm zijn. Door een foutief geïdentificeerde trojan kunnen er miljoenen apparaten geïnfecteerd raken, wat een kostenpost van miljoenen euro's als gevolg heeft.
Hierdoor zijn er een aantal belangrijke overwegingen die moeten worden toegepast als AI in beveiligingssystemen wordt gebruikt:
- De beveiligingsleverancier moet de essentiële vereisten voor de prestaties van AI-elementen in de werkelijke, mogelijk vijandige wereld begrijpen en zorgvuldig aanpakken. Deze vereisten omvatten een krachtige beveiliging tegen mogelijke aanvallen. ML- en AI-specifieke beveiligingsaudits en 'red-teaming' moeten belangrijke onderdelen zijn van de ontwikkeling van beveiligingssystemen waarbij AI-elementen worden gebruikt.
- Als de beveiliging van een oplossing wordt besproken waarbij AI-elementen worden gebruikt, moet je je afvragen in hoeverre de oplossing afhankelijk is van gegevens en architecturen van derden, aangezien veel aanvallen zijn gebaseerd op input van derden (bijvoorbeeld bedreigingsinformatiefeeds en openbare datasets, evenals vooraf getrainde en externe AI-modellen).
- ML- en AI-methoden moeten niet worden beschouwd als een wondermiddel. Ze moeten onderdeel zijn van een meerlaagse beveiligingsaanpak, waarbij complementaire beschermingstechnologieën en menselijke expertise kunnen worden gecombineerd en een aanvulling vormen op elkaar.
Het is belangrijk om te erkennen dat, hoewel Kaspersky uitgebreide ervaring heeft met het efficiënte gebruik van aspecten van AI-elementen zoals ML en het Deep Learning-onderdeel van de cyberbeveiligingsoplossingen, deze technologieën geen echte AI, oftewel Kunstmatige Algemene Intelligentie, zijn. Het duurt waarschijnlijk nog een hele tijd voordat machines onafhankelijk kunnen werken en de meeste taken geheel zelfstandig kunnen uitvoeren. Tot die tijd is voor bijna elk AI-element binnen de cyberbeveiliging de begeleiding en expertise van menselijke experts nodig om de systemen te ontwikkelen en te verfijnen, waardoor de vaardigheden na verloop van tijd toenemen.
Voor een gedetailleerder overzicht van populaire aanvallen op ML- en AI-algoritmen en de methoden van beveiliging tegen deze bedreigingen, lees je onze whitepaper 'AI under Attack: How to Secure Machine Learning in Security System'.
Gerelateerde producten




 Whitepaper
Whitepaper
WhitepaperMachine Learning for Malware Detection
Whitepaper
WhitepaperMachine learning and Human Expertise
Whitepaper
WhitepaperAI under Attack: How to Secure Machine Learning in Security System